浅谈高中课本中的概率部分
开始之前,今天是一个特殊的日子——毛主席的诞辰,在此缅怀
起因
昨天看到我的高中数学老师写了一篇关于百分位数在高中课本中定义及计算的文章,在翻阅茆先生的书时,看到了有关分位数的定义,不过书中仅讨论了连续的情况。在老师的文章里面,了解到对于离散数据的分位数的计算,有很多种定义方法,于是,昨天晚上,我忍不住好奇心,又去翻阅了一下茆先生的书,并在网上搜索了一些相关资料,惊奇的发现,其实高中课本中对于涉及到概率论的东西,很多方面是有待完善的,或者说,有些实际上很重要的部分却很容易被大部分高中生所忽视。故今天想要发出来和大家一起分享一下
(注:本篇文章仅个人观点,知识体系可能还不够完善,如有错误,请多包涵~)
我们先来看看高中课本中的一些定义,并给出补充完善
(ps:由于作者本人不是很欣赏北师大版的课本,并且人教版课本相对来说比较权威也是大部分同学使用的,故下面仅引用人教版课本内容)
其实翻阅了一下人教版电子书上关于概率以及统计的部分,还是觉得人教版课本编写的还是相当好的,可以说没有什么不严谨的地方,只能说有些因为阶段性教育问题而不全面的地方,下面我们就展示几个概念~
PART1:百分位数



这是人教A版课本中对于百分位数的解释,至于为何要放阅读和思考部分,后面说。
我上学的时候,没有老师跟我说过这个东西是怎么来的,只是记住公式会做题即可,想必相当一部分同学的老师也是如此。然而,课本中给出的百分位数定义其实只是众多定义中的一种,但并非课本不严谨,不知道大家有没有注意到,第一张图的右侧蓝色框中,提到了—— 是的,对于离散数据的分位数,由于不同场景下的应用需求不同,计算方法上也给出了不同定义,以下为搜集的资料,进行详细叙述~
是的,对于离散数据的分位数,由于不同场景下的应用需求不同,计算方法上也给出了不同定义,以下为搜集的资料,进行详细叙述~
一、基本概念对于离散数据集 ,求第 分位数()。
核心问题:离散分布函数是阶梯函数,逆函数不唯一。
二、Hyndman & Fan (1996) 的9种类型设 分位数位置,,(小数部分)。
类型1(逆经验分布函数,右连续)
类型2(类似类型1,但连续化在跳跃中点)
类型3(最近整数)
- (四舍五入)
或规定:若 半整数则取较小/较大值。
特点:倾向于取样本值。
类型4(线性插值,旧定义)
类型5(中位数无偏,基于 Hazen)
类型6(Weibull,Excel PERCENTILE.EXC)
类型7(默认,Excel PERCENTILE.INC,R默认)
类型8(中位数无偏,基于 Blom)
类型9(基于 Tukey)
三、常见教材的简化方法
方法A:向上取整法
- 若 是整数:取第 个和第 个数据的平均值
(这与类型2类似)
方法B:位置公式法
四、不同类型比较示例数据:(),求第0.3分位数(30%分位数)
五、选择原则
- R:
quantile(..., type=7) 默认 - Excel:
PERCENTILE.INC(类型7),PERCENTILE.EXC(类型6) - Python numpy:
np.percentile(..., interpolation='linear') 对应类型7 - Python pandas:
Series.quantile() 默认类型7
六、中位数特例()对于离散数据,中位数通常定义为:
这与类型2、7等在 时一致,但与类型1可能不同。
七、分组离散数据当数据已分组为频数表,计算分位数需要:
其中:
既然都说到这了,我再给一下连续类型分位数的计算公式吧
(以下来自茆先生的书)


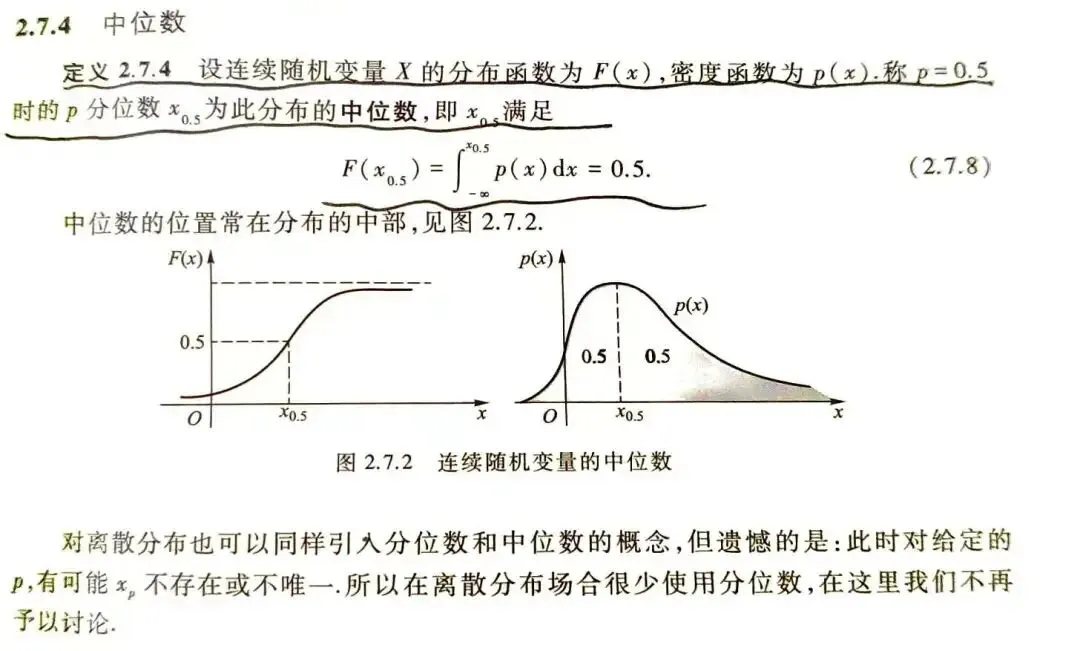
总的来说,实际上,无论离散数据还是连续数据,他们的分位数是有统一的定义的,但没有统一的计算方式,这也正是高中时候我们学到这里所不了解的深层知识。
忘记说了,上面我还给了一个阅读材料,是因为在老师的文章里,我看到上课有同学是从类似于阅读材料中的角度去理解分位数的,也是一种较为直观的方式,之前在b站上的小谷老师(对就是内个很厉害的小女孩哈哈)那里看到过这种理解,实际上也是课本中的东西。
PART2:方差与标准差



这是来自人教版课本中对方差及标准差的定义,实际上,是严谨的,也清晰阐述了样本和总体这两种方式,同时,不知道大家是否注意到,第二张图片右侧的小蓝框里给出的——  这也是我下面想要强调的一点,以下给出详细解释。
这也是我下面想要强调的一点,以下给出详细解释。
1. 总体方差对于总体(所有研究对象),方差定义为每个数据与总体均值之差的平方的平均值。
设总体有 个数据:,总体均值为:
总体方差为:
总体标准差为:
2. 样本方差对于样本(从总体中抽取的部分),我们使用样本均值 代替 ,但分母有特殊选择。
设样本有 个数据:,样本均值为:
样本方差(无偏估计)为:
样本标准差为:
二、为什么分母不同?—— 无偏性解释
关键问题用样本均值 代替总体均值 时,会系统性地减小平方和。
数学推导
令
可以证明:
取期望:
因为:
所以:
因此:
而
结论用 估计 会系统性地低估;用 才是无偏估计。
实际上,我认为,高中对此或许应该作为阅读材料补充一个概念——自由度。以下为查阅资料后的简要补充说明。
样本方差中的自由度
对于样本方差:
分母用 而不是 ,原因如下:
- 影响:在计算 时,虽然我们有 个离差 ,但它们满足一个线性约束:
这意味着,如果我们知道了 个离差,第 个离差就被确定了。因此独立的离差只有 个。
自由度(丢失了 1 个自由度用于估计均值)。
一些性质:
- 无偏性:用 作为分母, 才是总体方差 的无偏估计。
- 几何解释:在 维空间中,数据点向量到“均值向量”(所有分量相等的向量)所在直线的垂直投影空间维度是 。
PART3:众数
 在人教版的课本中,不知道是我漏掉了还是什么,只在这里发现了对于众数的说明。或许是因为初中课本上已经给出过众数的具体说明,于是高中课本就省略了,于是显然,在这里,高中的大部分同学会想当然的认为——频数直方图中最高矩形的中点就是众数。下面给出搜集资料后的进一步严谨地说明:
在人教版的课本中,不知道是我漏掉了还是什么,只在这里发现了对于众数的说明。或许是因为初中课本上已经给出过众数的具体说明,于是高中课本就省略了,于是显然,在这里,高中的大部分同学会想当然的认为——频数直方图中最高矩形的中点就是众数。下面给出搜集资料后的进一步严谨地说明:
一、理论基础:概率分布中的众数
1. 离散随机变量
设离散随机变量 的概率质量函数为
众数定义为使概率质量函数最大的那些取值:
其中 是 的取值空间。
性质:
- 如果所有 都有相同的 (如离散均匀分布),则 (或说无唯一众数)
2. 连续随机变量
设连续随机变量 的概率密度函数为 。
众数是密度函数 的(局部)极大值点:
- 局部众数:若存在区间 和点 ,使得 对所有 成立,则 是局部众数
数学表达: 对于连续可微的,众数满足必要条件:
(即导数为零且二阶导为负)
注意:
二、样本众数(经验众数)
1. 离散样本
对于样本数据 :
令 表示值 出现的频数。
样本众数定义为:
这是总体众数的自然估计,当样本独立同分布时,随着 , 收敛到总体众数(在适当条件下)。
2. 连续样本(或分组数据)
对于来自连续分布的样本,直接使用离散定义无意义(每个值可能唯一)。需要密度估计:
方法一:直方图法
方法二:核密度估计法
用核函数 和带宽 估计密度:
样本众数为 的极大值点。
带宽选择影响结果:带宽太大 过度平滑,可能丢失众数;带宽太小 噪声过多,产生虚假众数。
以上资料是在网上以及书中查找后得到的较为严谨的说明,只是想告诉大家,实际上,课本中未曾提及到的众数的具体定义,是不够完善的,不过由于阶段性教育原因,也算有情可原,但个人觉得也许应该至少在课本中略作提及,以确保完整性。
PART4:样本相关系数

 以上是在人教版课本中找到的关于线性回归中相关系数的定义,有一个很容易被大家忽视的点,不过在我印象中,25届的模考卷中我曾做到过以这个点挖坑的题目。也就是课本右侧的紫色小框里的内容——
以上是在人教版课本中找到的关于线性回归中相关系数的定义,有一个很容易被大家忽视的点,不过在我印象中,25届的模考卷中我曾做到过以这个点挖坑的题目。也就是课本右侧的紫色小框里的内容—— 
实际上,与分位数的不同计算方式类似,对于相关系数,也有非常多的计算方式,以下给出查阅资料后的简要说明:
一、按变量类型选择
连续-连续变量
Spearman(斯皮尔曼):单调关系,用秩次
= 两变量秩次差
Kendall's τ(肯德尔):小样本,解释为一致对比例
连续-二分变量
分类-分类变量
二、对于高级/特殊用途
探索复杂关系
控制变量
其他
(同时,r对异常值是敏感的,一个离群点可能会大幅度改变r的值)
以上一方面是为了进一步说明课本中给出的公式仅度量线性关系,另一方面也是想说明由于不同的应用场景差异,计算方法也有所不同,课本上给出的仅仅是一种类型的计算方式。
PART5:独立性检验
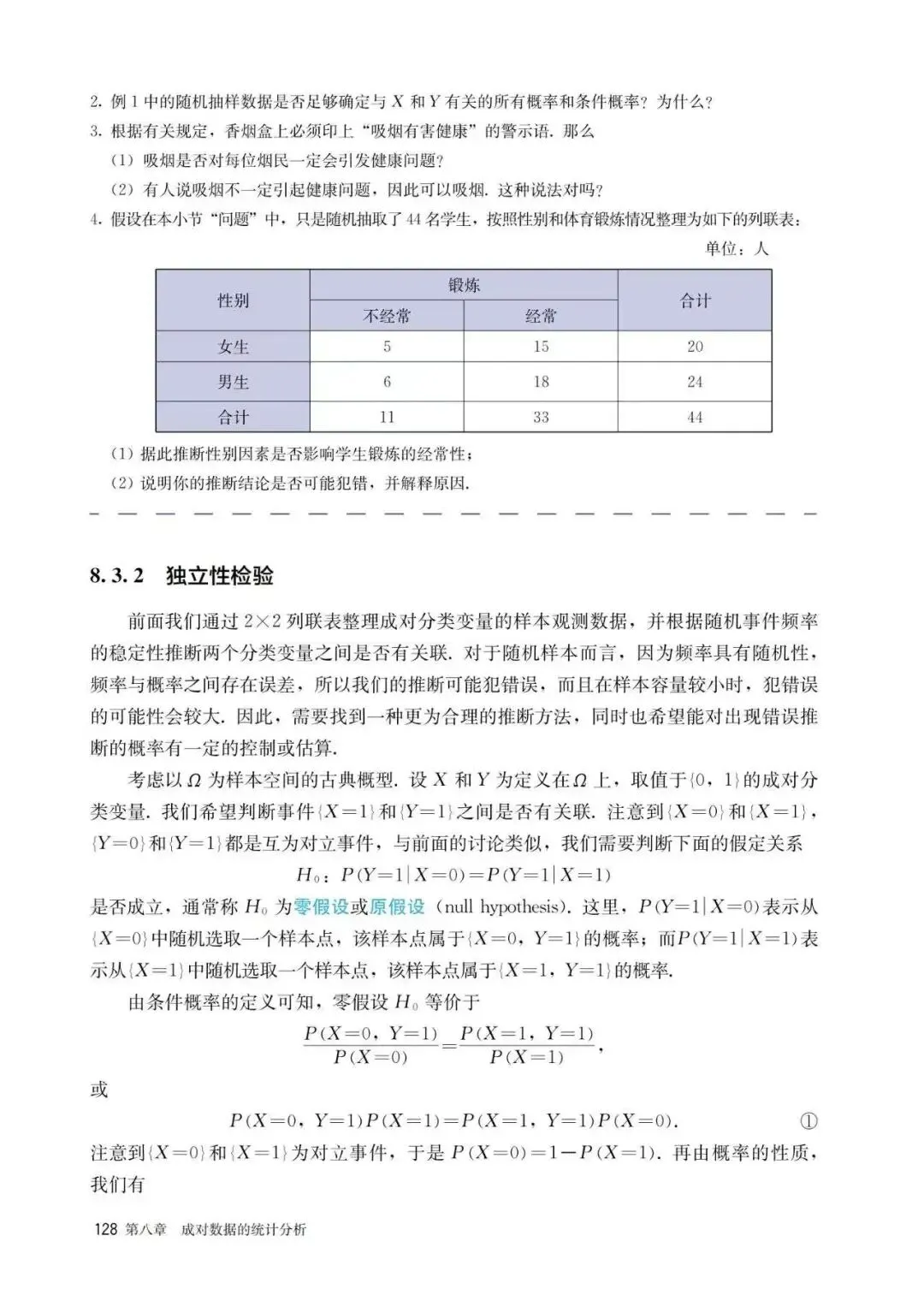
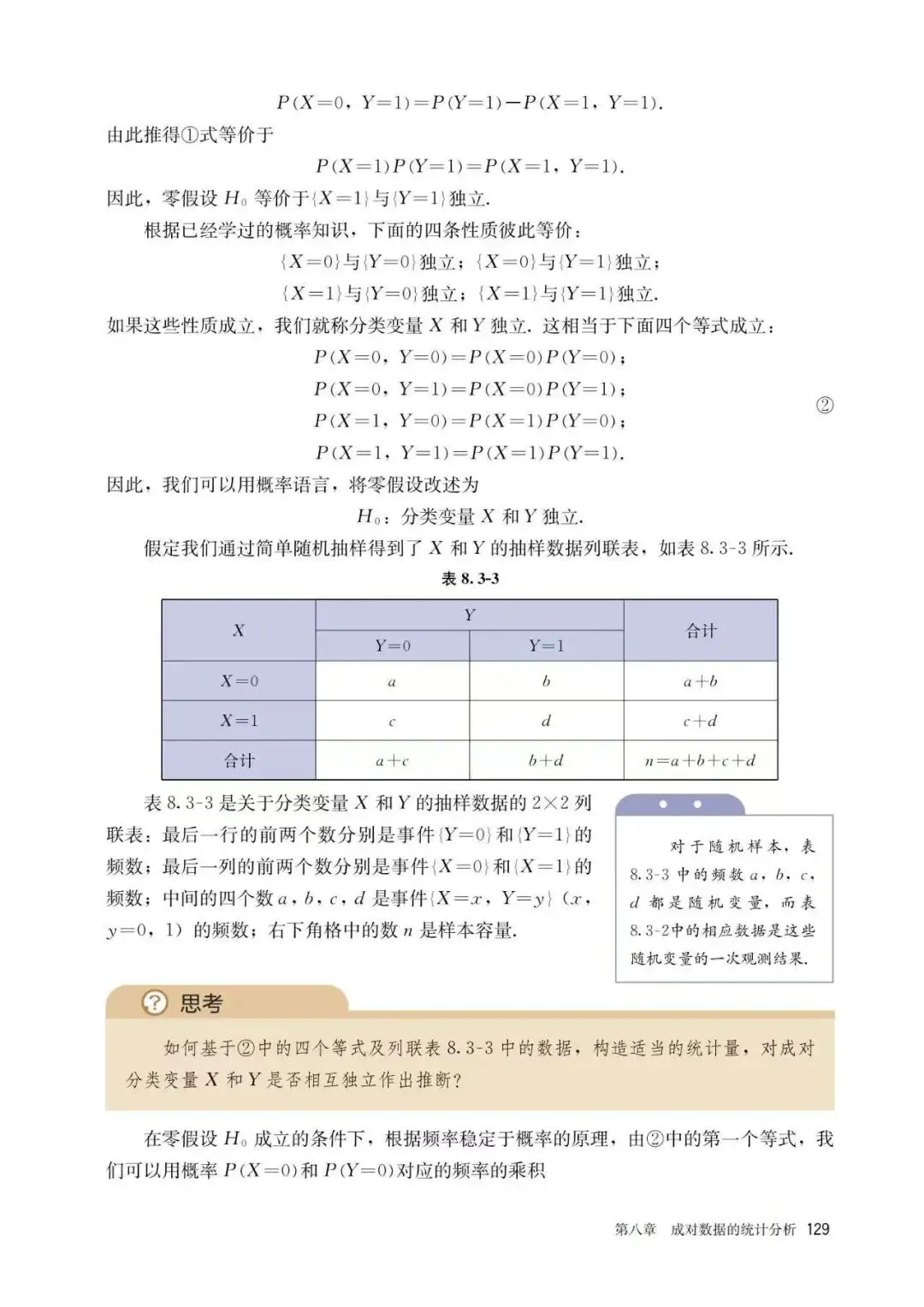

 以上是人教版课本中给出的独立性检验的定义及计算判断方法,实际上,个人觉得这里是不够完善的,因为可能会有一部分同学错误地认为,卡方越大关联性越强,这个理论是不严谨的。以下给出在高中课本中不够完善的具体原因说明及补充知识:
以上是人教版课本中给出的独立性检验的定义及计算判断方法,实际上,个人觉得这里是不够完善的,因为可能会有一部分同学错误地认为,卡方越大关联性越强,这个理论是不严谨的。以下给出在高中课本中不够完善的具体原因说明及补充知识:
1. 期望频数太小的问题
卡方检验的近似要求每个期望频数不低于 5(有些宽松要求是 80% 单元格期望 ≥5 且最小期望 ≥1)。
如果期望频数太小,卡方分布近似很差,可能得出错误结论。
高中无论课本还是习题册上的某些题目会忽略这个问题
2. 只检验是否独立,不度量关联强度
卡方值大只说明“有关联”,但关联的强度则需要补充度量如:
由于高中课本上对此并未补充说明,可能会导致有些同学的误解。
3. 未说明卡方分布的自由度来源
对于 表,自由度 。
来源为:因为估计期望频数时用了 个边际合计约束(总合计固定,每行/列自由度为行数/列数减 1)。
4. 未提及卡方检验的方向性
卡方检验是双侧的,不能直接得出“A 组比 B 组更倾向某类别”的结论,需进一步比较比例。
实际上,对于卡方的计算,也有多种方式,不过有些复杂,在这里不再一一展示。
PART6:正态分布
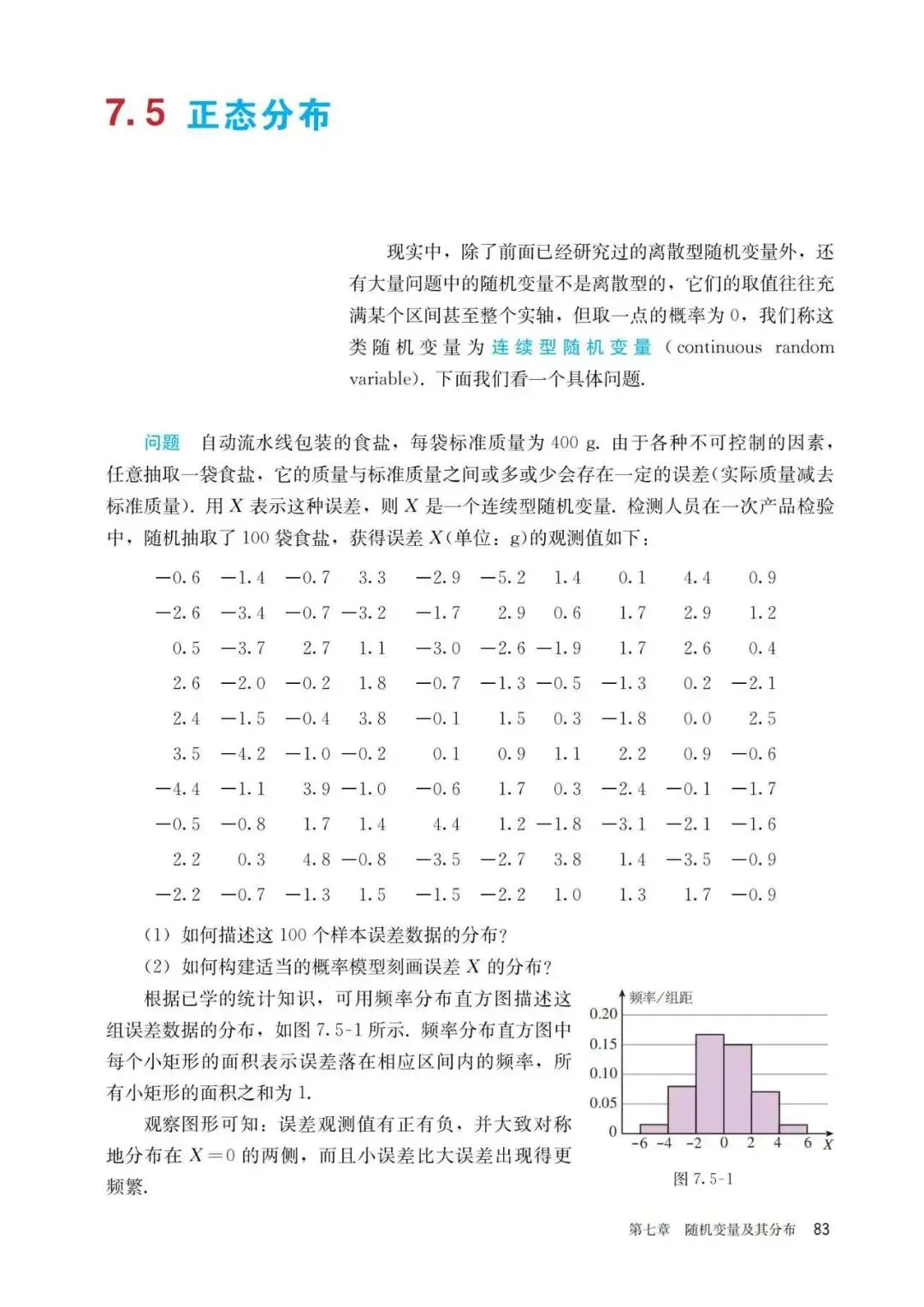
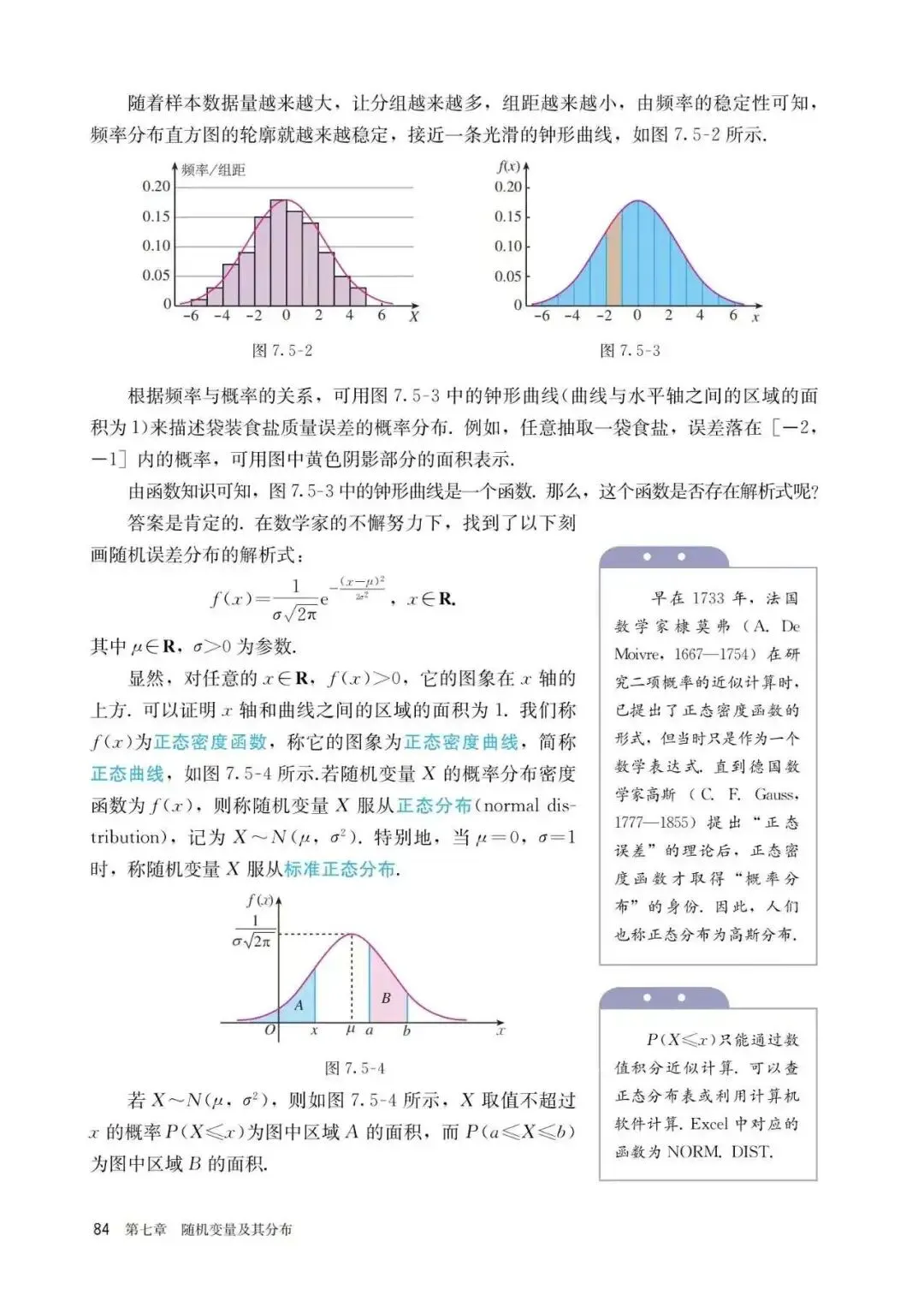
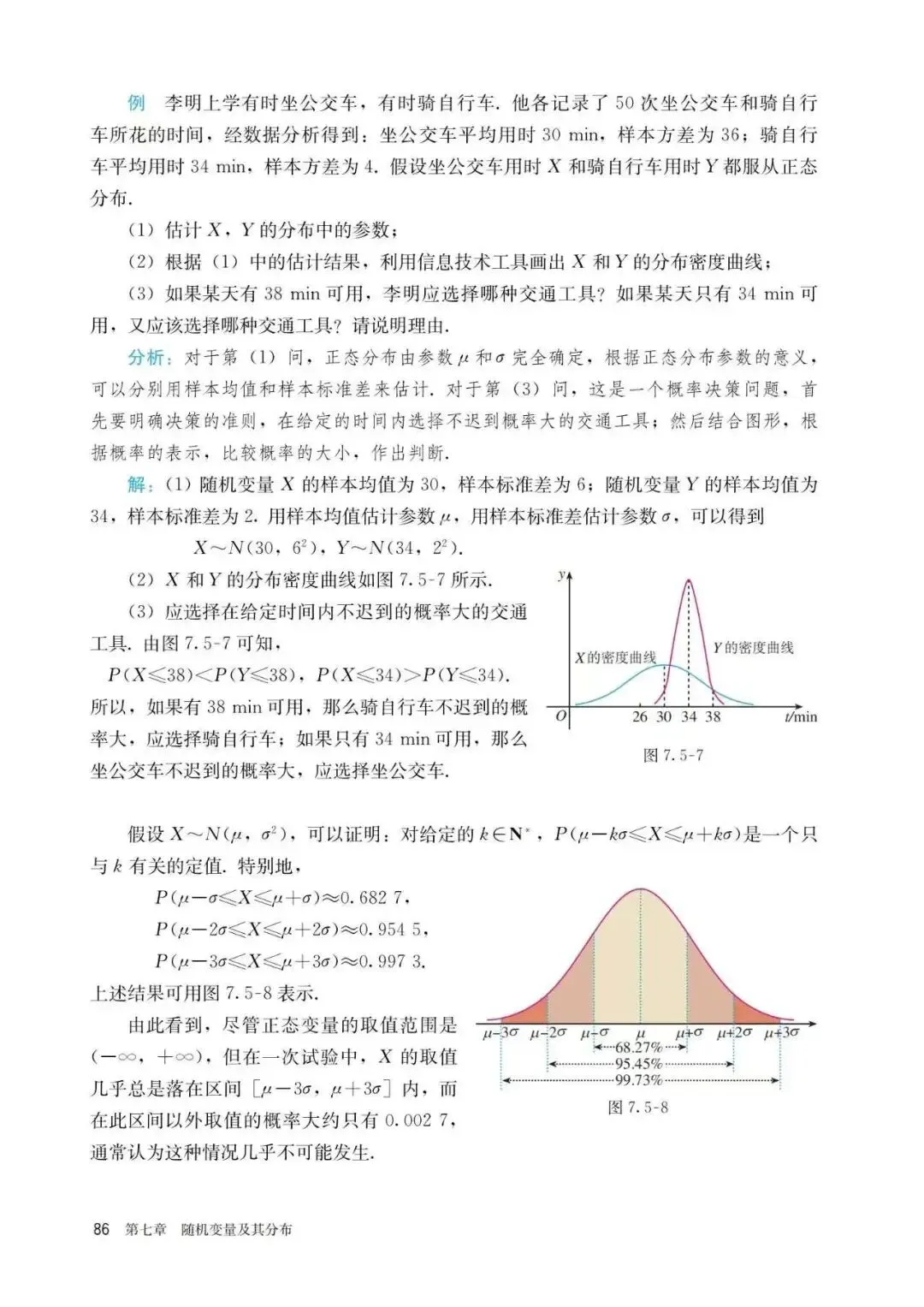 这是人教版课本中给出的对于正态分布的具体概念以及计算,我们会发现其实里面提到了密度函数这一概念,但并未深入解释概率密度这一含义,也并未给出所谓的3原则的应用条件与适用场景,个人感觉或许是应该稍作提及的,以下是对此的进一步解释与补充说明:
这是人教版课本中给出的对于正态分布的具体概念以及计算,我们会发现其实里面提到了密度函数这一概念,但并未深入解释概率密度这一含义,也并未给出所谓的3原则的应用条件与适用场景,个人感觉或许是应该稍作提及的,以下是对此的进一步解释与补充说明:
1. 概率密度函数的含义
核心思想:描述连续随机变量在某个取值点附近的可能性密集程度
关键点:
2. 标准正态分布表的来历起源:
来源:
用途:
3. 中心极限定理(CLT)核心内容:无论总体分布是什么形状,只要:
- 样本独立同分布(i.i.d.) 则样本均值的抽样分布近似服从正态分布:
4. 3σ原则的成立条件严格条件:数据必须服从正态分布
- 这是精确99.73%概率的前提 而在实际应用中,数据可能仅为近似正态 并非精确正态。
注意事项:
- 在金融数据(厚尾分布)中,极端值远多于正态分布的预测
实际上,了解这些后,会发现高中课本上的叙述是不全面的,但不能说不严谨(仅限人教版课本),不过在书上介绍这些确实过于深入了,但了解一下也不是什么坏事。
总结
这篇文章整理了差不多快三个小时,通过各种查阅资料,并与高中课本进行对照,完成了这篇文章。最后,再发表一些个人观点。
首先,人教版课本编的个人感觉是非常非常好的,无论从深度还是严谨性来说,都是很好的教材,只是有些内容个人感觉应该得到完善;
其次,对于高中老师(大部分)只强调公式记忆而不给出引导与解释,个人是不欣赏的,当然也不排除有些东西实在过于超纲(或者你的高中老师其实不会哈哈哈哈),但我觉得最基本的引导是要有的,数学只死记公式,或许就失去了它本身的魅力了;
最后,或许因为阶段性教育的原因,我们很少能看到这些背后更深入的东西,这里还是很鼓励并建议大家(高中生)如果在空闲的时候去主动了解一些背后的深层次的东西的,当然也了解大家可能受困于当下的教育模式,所以,兴趣使然吧,有兴趣可以了解一下,不要本末倒置就好~
课本固然权威,但实践出真知,盲从权威是断然不可取的。
速递速递
说一个最近感悟到的小事,发现人成长好像是不断祛魅的过程哈哈哈哈,很早之前有些很崇拜的人,或许是老师或许是同学,会因为自己的知识不断的丰富,而觉得内些人不再那么厉害,但是,至少对一种东西是永远不会祛魅的——知识。
最后,提前祝大家元旦快乐哈哈,希望2026年能再幸运点哈哈哈哈哈。 然后,由于今天是个特殊的日子,故再次于文末缅怀毛主席!

